はじめてのnumpy/pandas
2020 T.Takeda
numpy
数値の多次元配列を扱えるPythonライブラリ
my_1darray = np.array([1, 2, 3, 5, 7])
my_2darray = np.array([
[1,2],
[3,5],
[8,13]
])
my_3darray = np.array([
[[0,0,0],[0,0,0],[0,0,0]],
[[128,128,128],[128,128,128],[128,128,128]],
[[256,256,256],[256,256,256],[256,256,256]]
])
範囲選択
| data[:,2] | data[1] | data[:,[0,2]] | data[1:2,1:2] |
|---|---|---|---|

|

|

|

|
Vectorization
- いわゆるSIMD演算

💡32bitsで8ビット4つの演算が並列に一度にできる
💡64bitsの飽和加算命令だと、1回で8ビット8個の加算ができる
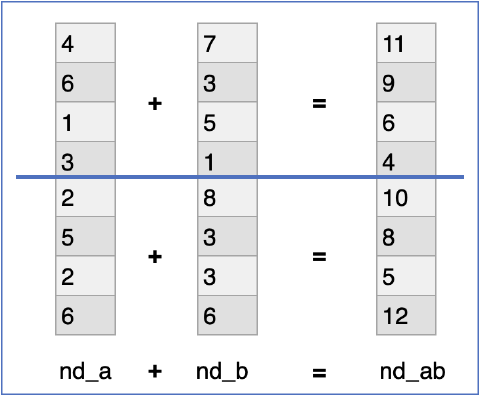
集計関数
多次元配列にmin/max/mean/sumなどの演算を行える
nd_a.min(axis=1)
nd_a.max(axis=1)
nd_a.mean(axis=1)
nd_a.sum(axis=1)
集計関数
- 行方向で集計
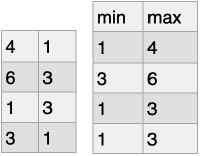
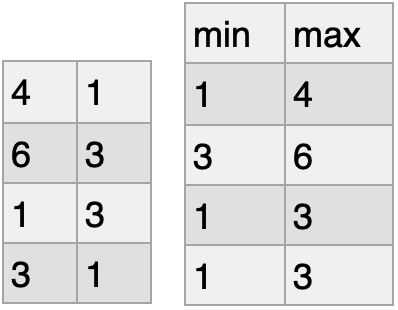
nd_a.min()
nd_a.max()
nd_a.mean()
nd_a.sum()
集計関数
- 列方向で集計
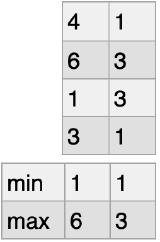
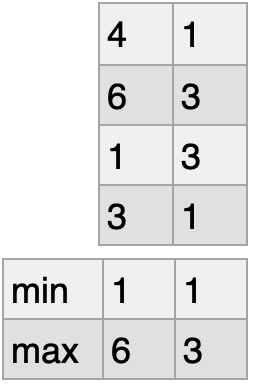
nd_a.min(axis=0)
nd_a.max(axis=0)
nd_a.mean(axis=0)
nd_a.sum(axis=0)
Boolean Indexing
nd_a_bool = nd_a < 4
| 4 | False |
|---|---|
| 6 | False |
| 1 | True |
| 3 | True |
| 2 | True |
| 5 | False |
| 2 | True |
| 6 | False |
nd_a[nd_a_bool]
| 1 |
|---|
| 3 |
| 2 |
| 2 |
Boolean Indexing
- 条件を満たす行だけに関数を適用できる


b = np.array([1,2,3,4,5,6,7,8])
b_odd = np.mod(b, 2) == 1
b_even = ~b_odd
b[b_even] = b[b_even] / 2
b[b_odd] = b[b_odd] * 3 + 1
Series/DataFrameへの拡張
統計目的の数値計算ライブラリだったため、数値しか扱えなかった
文字列なども扱えるようにしたい!
![]()
Series/DataFrame化したpandasへ進化
pandas
DataFrameオブジェクトを用いて効率的にデータ分析を行うためのPythonライブラリ
- Seriesは列指向、DataFrameはSeriesの集まり
- メソッドチェーンで書けるが、遅延評価や最適化はなされない
df.apply().drop() <- 無駄な演算が走る
df.drop().apply() <- 先に情報を落として計算する
💡最適化される体系もあるため、基本的にはメソッドチェーンを活用したい
ループはきれいに書けないし、遅い
- 手続き型の考え方は捨てる
- DataFrameに対してループは必要ない
- iterrowsは致命的に遅い
- iloc, loc, iat, atは何か考え方を間違えている
- 回したいならList/純粋なnumpyに持ち込んだ方がまだ速い
applyはきれいに書けるが遅い
- df.apply()は行ごとに関数適用するために、
- Seriesを取り出して、
- 書き換えて新しいSeriesを生成し、
- Seriesを書き戻す
- Seriesは列方向のデータ
- 1つの行データを書き換えるためにSeriesの再生成を何度も行う
- Pythonの関数呼び出しのオーバーヘッドも大きい
必要なデータだけ処理する
DataFrameは全データを抱え込んでいる
- 必要なSeriesだけを取り出して処理した方が早い
- メモリ効率、データコピー、再生成、関数呼び出しなどあらゆる面でパフォーマンスに効く
- pandasでは対象をselect/dropしてからmapと考える
DataFrameと行き来しない
- DataFrame<=>numpy/List/Dictなどの変換はオーバーヘッドが大きい
- DataFrameでやりきるか、最初からDataFrameを使わない
- tolist()は最後の一回
- ×DataFrame処理 -> df.tolist() -> DataFrame再生成 -> ...
データ型を明示的に意識する
基本的にはnumpyオブジェクト
- 型推論機構がpandasのバージョンにより異なる
- dtype/astypeで明示的に合わせる
組み込みの集計関数を知り、活用する
- groupby/agg
- fillna/dropna
- pivot/unstack
- merge/join
- window
- explode
- etc ...
APIを活用するために
-
APIリファレンス↗ を眺めて知っておく
- DataFrameにできる操作はSeriesにも大抵できる
-
組み込みの関数を使う
遅いロジックを自分で書くのは不具合を招く
sr.apply(lambda x: x if x else 0)
![]()
速くてシンプル
sr.fillna(0)
カラム選択、行選択
複数のカラムを選択
df[['username', 'email']]
= df.loc[:, ['username', 'email']]
区間のカラムを選択
df.loc[:, 'username':'age']
行選択
df.loc[['100','200','400']]
条件による行選択
20歳未満の行の、名前とメールアドレス列を取得
df.loc[df['age']<20, ['username', 'email']]
国が日本と中国の行のみ選択
df[(df['country'] == 'Japan') | (df['country'] == 'China')]
表記揺れを修正
mapと辞書でtypoを一括置き換え
mapping_dict = {
'upple': 'apple',
'epple': 'apple',
'bununu': 'banana',
'binini': 'banana'
}
buscket['fruits'] = buscket['fruits'].map(mapping_dict)
数え上げ
組み込み関数
buscket['fruits'].value_counts()
apple 49997
banana 3
Name: fruits, dtype: int64
小さい順に並べる
buscket['fruits'].value_counts().sort_index(ascending=True)
文字列置換
price列の"300Yen"文字列を300という数値に
buscket['price'] = buscket['price'].str.replace('Yen', '').astype(int)