はじめてのRDB
2020/06 T.Takeda
データベース基礎
Database(DB)とは
- データを蓄えて、いい感じに追加/更新/検索/削除するための仕組み
- (データが大量にあっても)速いとうれしい!
- いろんな条件で検索したい!

DBの活用どころ
| 形態 | 適したデータ量 |
|---|---|
| File Text |
数サンプルのデータ 例えば、疫学、臨床試験データなど |
| File Excel/CSV |
数MB級のデータ アンケート結果、実験データ、エントリーシートなど |
| Database | MB〜GB級のデータ 社員データ、在庫管理システムなど |
| File Storage Raw/AVRO/Parquet/ORC |
GB〜TB級のデータ 顧客データ、Webページビュー履歴など |
| File Storage +Compressed |
TB〜PB級のデータ SNS、センサーデータ、画像データなど |
データの持ち方
- テキスト、DB、ファイルなどデータ量、用途に合わせて選択する
- 少量のデータや膨大な画像をDB管理にすると使い勝手が悪い
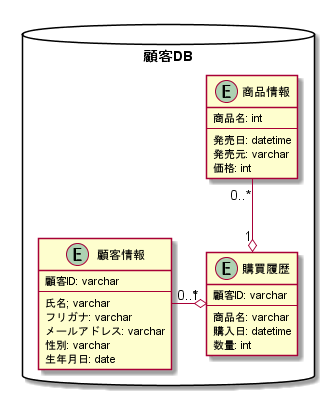
RDBとは
- Relational Database
- 関係モデルを用いて設計されたデータベース
- テーブルとテーブルの関係を考慮して設計する
代表的なDBモデル
- RDB
- 関係データモデル
- 複雑な関係性の固定構造をもつ大量データに強い
- MySQL、PostgreSQL、AWS Auroraなど
- NoSQL(RDB以外)
- Key-Value形式
- シンプルな関係性の自由構造の大量データ処理に強い
- MongoDB、AWS DynamoDB、GCP BigTableなど
💡NoSQLがよいかRDBがよいかはケースによる
SQL(Structured Query Language)
- リレーショナルデータベースのクエリ言語、あるいはその実装
- 厳密にはSQL = リレーショナルデータベースではない
- 本資料ではNoSQLの話はしない
- SQLのベストプラクティスとかなり異なる
DB定義(DDL)
Data Definition Language
- データオブジェクトを作成(CREATE)
- データオブジェクトを削除(DROP)
- データオブジェクトを変更(ALTER)
- 全行データを削除(TRUNCATE)
データ操作(DML)
Data Manipulation Language
- データを挿入(INSERT)
- データを更新(UPDATE)
- データを削除(DELETE)
- データを検索(SELECT)
データ制御(DCL)
Data Control Language
- 権限を付与(GRANT)
- 権限を剥奪(REVOKE)
- トランザクションを開始(BEGIN)
- トランザクション処理を確定(COMMIT)
- トランザクション処理を取り消す(ROLLBACK)
- トランザクションを終了(END)
正規形
データベースの管理や更新を楽にするためのプラクティスの一つ
- 第一正規形
- 第二正規形
- 第三正規形
💡第三正規形くらいまでは知っておき、普段から意識する
第一正規形
データがスカラ値になっていること
- 値として、表、配列、カンマ区切りの値などが入っているのは非正規形

💡スカラ値でなければ、そもそもRDBに格納する意味がない状態
💡交差テーブルを用いないJaywalkingなどを引き起こす
![]()
解消するためには、行として分解する
| グループ | 社員群 |
|---|---|
| グループ1 | 社員A,社員B,社員C |
| グループ2 | 社員B,社員C |
![]()
| グループ | 社員群 |
|---|---|
| グループ1 | 社員A |
| グループ1 | 社員B |
| グループ1 | 社員C |
| グループ2 | 社員B |
| グループ2 | 社員C |
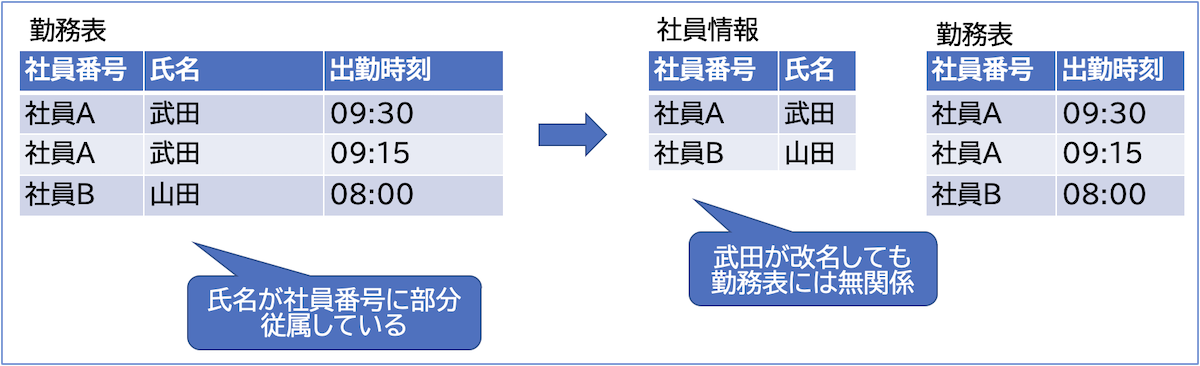
第二正規形
第一正規形 + 非キー属性が候補キーに対して完全従属
![]()
重複行を解消し、対応を整合させる
| 社員番号 | 氏名 | 出勤時刻 |
|---|---|---|
| 社員A | 武田 | 09:30 |
| 社員A | 武田 | 09:15 |
| 社員B | 山田 | 08:00 |
![]()
| 社員番号 | 氏名 |
|---|---|
| 社員A | 武田 |
| 社員B | 山田 |
| 社員番号 | 出勤時刻 |
|---|---|
| 社員A | 09:30 |
| 社員A | 09:15 |
| 社員B | 08:00 |
💡氏名が社員番号に部分従属している
💡第二正規形では、"武田"が改名しても勤務表には無関係
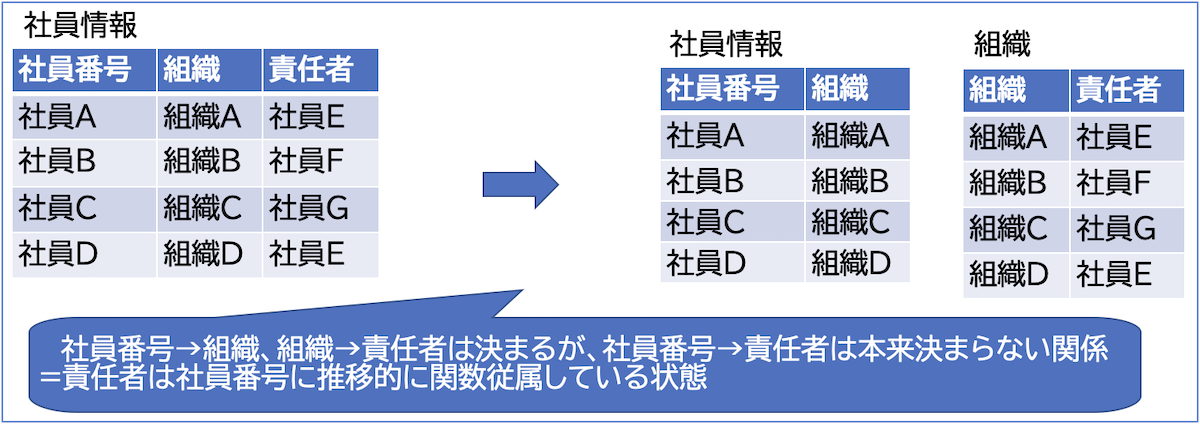
第三正規形
第二正規形 + 非キー属性が候補キーに対して推移的関数従属していない
![]()
テーブルを切り離し、従属関係を解消する
| 社員番号 | 組織 | 責任者 |
|---|---|---|
| 社員A | 組織A | 社員E |
| 社員B | 組織B | 社員F |
| 社員C | 組織C | 社員G |
| 社員D | 組織D | 社員E |
![]()
| 社員番号 | 組織 |
|---|---|
| 社員A | 組織A |
| 社員B | 組織B |
| 社員C | 組織C |
| 社員D | 組織D |
| 組織 | 責任者 |
|---|---|
| 組織A | 社員E |
| 組織B | 社員F |
| 組織C | 社員G |
| 組織D | 社員E |
💡社員番号→組織、組織→責任者は決まるが、
社員番号→責任者は本来決まらない関係性
💡= 責任者は社員番号に推移的に関数従属している状態
後続の正規形
- ボイスコッド正規形
- 第4正規形
- 第5正規形
💡やりすぎると利便性やパフォーマンスを犠牲にすることになる
キーに関して
プライマリーキー
- テーブルごとに一つ定義された候補キー
- 主キー以外の候補キーは代理キーという
自然キーと人工キー
- 格納すべき値をキーとしたものを自然キーという
- 社員番号など値そのもの
- 利用者が必要としないがシステム内部で生成したキーは人工キー
- 重複を避けるためのUUIDなど
代替キー(Surrogate Key)
- 自然キーの一意性の担保が難しい場合、更新が多い場合に代替キーを用いることがある
💡例えば、ユーザー名が変更可能な場合にユーザー名を主キーとすると
ユーザーの一意性を担保できない場合
- テーブル間の主キーによる依存を断ち切ることになる(Relational DBにも関わらず)
💡NoSQLではキーは一意にするためにUUIDを用いることは一般的
単一キーと複合キー
- 単一キーは単体で一意になるキー
- 複合キーは主キーがすべて揃わないと一意にならない
代替キーかつ単一キー
UUIDが代表例
- Pros
- 複合キーを使わず、単一のキーにできる
- uuidでクエリーをかければSQLがシンプルになる
- 主キーが値の更新の影響を受けなくなる
- Cons
- 意味のない値を管理する必要がある
- 一意性の担保をアプリケーションが担う
- テーブル間の依存が見えづらくなる
外部キー制約
- DB間の関係を設定し、データの整合性の保証をDBに任せる
- 親テーブルにない情報を子テーブルに登録しようとするとエラー
- 子テーブルに存在するデータを親テーブルから消そうとするとエラー
![]()
親テーブル
| 社員番号 | 組織 |
|---|---|
| 社員A | 組織A |
| 社員B | 組織B |
| 社員C | 組織C |
| 社員D | 組織D |
子テーブル
| 組織 | 責任者 |
|---|---|
| 組織A | 社員E |
| 組織B | 社員F |
| 組織C | 社員G |
| 組織D | 社員E |
💡データ構造として保証すべきことを、アプリケーションで保証する必要がなくなる
![]()
- 追加、更新、削除の操作順序を意識する必要がある
- 親テーブルを作成してから子テーブルを作成する
- 子テーブルから削除して親テーブルから削除する
| 社員番号 | 組織 |
|---|---|
| 社員A | 組織A |
| 社員B | 組織B |
| 社員C | 組織C |
| 社員D | 組織D |
| 組織 | 責任者 |
|---|---|
| 組織A | 社員E |
| 組織B | 社員F |
| 組織C | 社員G |
| 組織D | 社員E |
💡子テーブル操作時に親テーブルのロック状態を意識しないとデッドロックする
プログラミング言語からのSQLの利用
SQLとプログラミング言語
- インピーダンス・ミスマッチ
- SQLはデータ操作に特化したクエリー言語
- オブジェクト指向言語はデータをオブジェクトに集約したい
- ジレンマ
- クエリーを最適化するとオブジェクト指向でなくなる
- オブジェクトとして扱いやすくするとクエリーが複雑になる
SQLと関数型言語
- 集合に対しての操作として思考が似ている
- SQLにループや代入はなくてよい
- 関数型言語にループ処理や再代入はなくてよい
- 宣言型プログラミング言語
- クエリーはデータの取得方法を宣言
- 関数型言語は関数適用を宣言
- 数理論理学に基づく言語(圏論からみれば同じもの)
- 関数型言語は関数を扱う(トポス)
- SQLは集合を扱う(集合論)
DAO、ORM
- DAO
- Data Access Object
- オブジェクト指向言語からデータアクセスを行うためのデザインパターン
- data.pyはどちらかというとこちらの思想
- ORM
- Object-Relation Mapping
- Mapper/マッパーと呼ばれる
- Pythonでは、sqlalchemyが代表的
行指向/列指向/ドキュメント指向
データの持ち方により、保存方法、取得方法、演算方法の効率に影響する
![]()
行指向
- 大量の列に対する処理が効率的に行える
- 行を絞ってデータを部分的に取得できる
- MySQLなど
| User | Item1 | Item2 | … | … | ItemN | ||||
|---|---|---|---|---|---|---|---|---|---|
| A | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
| B | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 |
💡ユーザーごとに購買アイテムを参照したい、など
![]()
列指向
- 大量の行に対する処理が効率的に行える
- 列を絞ってデータを部分的に取得できる
- SAPなど商用に多い
| Class1 | Class2 |
|---|---|
| 1 | 1 |
| 0 | 1 |
| 0 | 0 |
| 1 | 0 |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
💡授業の履修状況を確認したい、など
![]()
ドキュメント指向
- 階層構造データをそのまま保持
- XMLやJSONのようなオブジェクト構造
{
'name': 'Takeda',
'id': '94T0115J',
'organization': 'cjgg'
}
💡持つ情報が個別に異なる、スパースなデータ、など
三値論理
三値論理はルール化して避けた方がよい
- True/False/NULL
- str/empty/NULL
- NULLはSQLでうまく扱えないので原則入れない方がよい
- =演算子はNULLとの演算結果は不定
- IS NULLとする
💡JavaScriptのundefined/nullやPythonのNullも同じ
💡HaskellならMaybeモナドでうまく扱える
インデックス
- テーブルに対して貼られる行の番号
- インデックスでのNULL利用はパフォーマンスが低下する
NULL
- ということで、使用を避ける
セキュリティ
DBの重要性
- 一番重要な情報が格納されている場所
- サービスのアカウントやパスワードが狙われるが、真の目的はその先の情報
- 情報が漏洩、改ざん、損失してはいけない
💡そのためにセキュリティ対策、冗長化が必要
💡コストに直結するため、RTO/RTPを適切に設定する
SQLへの攻撃
- SQLインジェクション
- 外部から与えられた値がクエリーに含まれる場合、不正なSQLを実行できる可能性がある
- 必ずエスケープし、ただの文字列として処理する
- 実際にこれができる状態のサービスも世にある
- 日本語のテーブル名、項目名は海外からの攻撃に強い
- かもしれない・・?
- utf8mb3 -> utf8mb4にしよう